
이번 글에서는 오는 7월 미국 캘리포니아주 샌디에이고에서 개최되는 자연어 처리(NLP) 및 인공지능(AI) 분야 최고 권위 학술대회인 ACL 2026에서 발표될 네이버클라우드의 논문(Enhancing Hallucination Detection via Future Context)을 소개합니다.
이주성 (NAVER Cloud)
박천복 (NAVER Cloud, KAIST)
조휘열 (NAVER Cloud)
김정훈 (NAVER Cloud, KAIST)
박준석 (NAVER Cloud, NAVER AI Lab, University of Richmond)
LLM 환각 검출은 왜 중요할까
LLM은 이제 질의응답부터 문서 작성, 블로그 콘텐츠 생성, 내용 요약까지 다양한 영역에서 자연스럽게 활용되고 있습니다. 모델의 답변은 점점 더 유창하고 설득력 있게 발전하고 있지만, 문제는 그럴듯함이 곧 사실성을 의미하지는 않는다는 점입니다. LLM이 생성한 글에는 실제로 존재하지 않는 사건, 잘못된 인과관계, 과거 문맥과 모순되는 주장, 혹은 검증되지 않은 정보가 포함될 수 있습니다. 이러한 현상은 일반적으로 환각(Hallucination)이라고 불립니다.
특히 블로그 글이나 온라인 게시물처럼 최종 결과물만 공개되는 환경에서는 문제가 더욱 복잡해집니다. 우리는 해당 글이 어떤 모델에서 생성되었는지, 어떤 프롬프트가 사용되었는지, 생성 과정에서 모델이 어떤 확률 분포를 기반으로 문장을 만들었는지 알 수 없습니다. 즉 생성 모델의 내부 정보에 접근할 수 없는 블랙박스 환경에서 환각 여부를 판단해야 하는 상황에 놓이게 되는 것이죠.
예를 들어 사용자가 “연말정산에서 월세 세액공제와 카드 소득공제를 동시에 받을 수 있어?”라고 질문했다고 가정해보겠습니다. 만약 모델이 초기에 잘못된 세법 정보를 생성하면, 이후 설명 역시 그 잘못된 전제를 바탕으로 이어질 가능성이 높습니다. 즉 하나의 작은 오류가 이후 문맥 전체를 오염시키게 됩니다.
기존 환각 검출 방식의 한계
LLM 환각을 검출하는 방법은 크게 세 가지 흐름으로 나눌 수 있습니다.
첫 번째는 불확실성 기반 방법입니다. 모델이 특정 토큰을 생성할 때 얼마나 낮은 확률로 예측했는지, 혹은 모델 내부의 Confidence가 낮은지를 활용하는 방식입니다. 다시 말해, 답변을 생성하는 과정에서 모델이 해당 내용을 얼마나 정확하다고 판단했는지를 활용하는 것이죠. 그러나 이 방법은 생성 모델의 Logits나 Token-level Probability 같은 모델의 내부 정보에 접근할 수 있어야 합니다. 따라서 API 형태로만 제공되는 모델이나 이미 생성된 외부 콘텐츠를 검증해야 하는 상황에서는 필요한 정보를 얻기 어렵습니다.
두 번째는 샘플링 기반 방법입니다. 동일한 질문에 대해 여러 응답을 다시 생성한 뒤, 원래 응답과 얼마나 일관성을 유지하는지를 확인하는 방식입니다. 대표적인 예로는 SelfCheckGPT가 있습니다. 이 방법은 여러 개의 대체 응답을 생성한 뒤, 특정 문장이 다른 여러 샘플에서도 반복적으로 등장하는지를 분석합니다. 사실에 기반한 내용이라면 여러 샘플에서 유사하게 등장할 가능성이 높고, 환각이라면 샘플마다 표현이 흔들리거나 서로 모순될 가능성이 높다는 가정에 기반합니다.
이 외에도 검색을 통해 확보한 문서를 활용해 환각 여부를 판단하는 방법도 존재하는데요. 다만 검색 기반 접근 역시 몇 가지 한계를 가집니다. 우선 추가적인 검색 비용이 발생하며, 검색 결과 자체의 품질과 신뢰성을 보장하기 어렵습니다. 검색된 문서가 오래되었거나 부정확할 수도 있고, 아예 필요한 정보가 공개 웹에 존재하지 않을 가능성도 있기 때문이죠. 예를 들어 기업 내부 문서, 비공개 지식베이스, 사내 정책, 특정 서비스의 내부 동작 방식처럼 접근이 제한된 정보가 필요한 경우에는 검색만으로 충분한 근거를 확보하기 어렵습니다.
본 논문에서는 이러한 제약을 고려해, 검색이나 생성 모델의 내부 정보에 의존하지 않는 블랙박스 기반 환각 검출 방법을 제안합니다.
핵심 아이디어: 환각은 미래 문맥으로 전파된다
논문에서 가장 흥미로운 관찰 중 하나는, 현재 문장이 환각이라면 이후에 이어지는 문장들 또한 환각일 가능성이 높아진다는 점입니다.
예를 들어 모델이 다음과 같은 문장을 생성했다고 가정해 보겠습니다.
“1969년에 달은 지구 궤도에서 영구적으로 제거되었다.”
이 문장은 명백히 잘못된 정보입니다. 하지만 LLM은 이후 문장에서도 이러한 잘못된 전제를 자연스럽게 이어가려는 경향을 보입니다.
“그 이후 인공위성이 달의 역할을 대신해 지구 자전을 안정화했다.”
“과학자들은 달이 사라진 뒤 지구 기후가 어떻게 변화했는지 연구하고 있다.”
이처럼 한 번 잘못된 정보가 생성되면 이후 문맥은 그 오류를 자연스럽게 이어받고, 이를 기반으로 추가적인 잘못된 내용을 계속 생성합니다. 즉 한 번 생성된 오류가 이후 문맥 전체로 퍼져나가며 추가적인 환각을 만들어내는 것이죠. 논문에서는 이러한 현상을 Snowball Effect라고 설명하는데요. 작은 오류가 문맥을 따라 누적되면서 뒤로 갈수록 더 큰 환각으로 확장된다는 의미입니다.
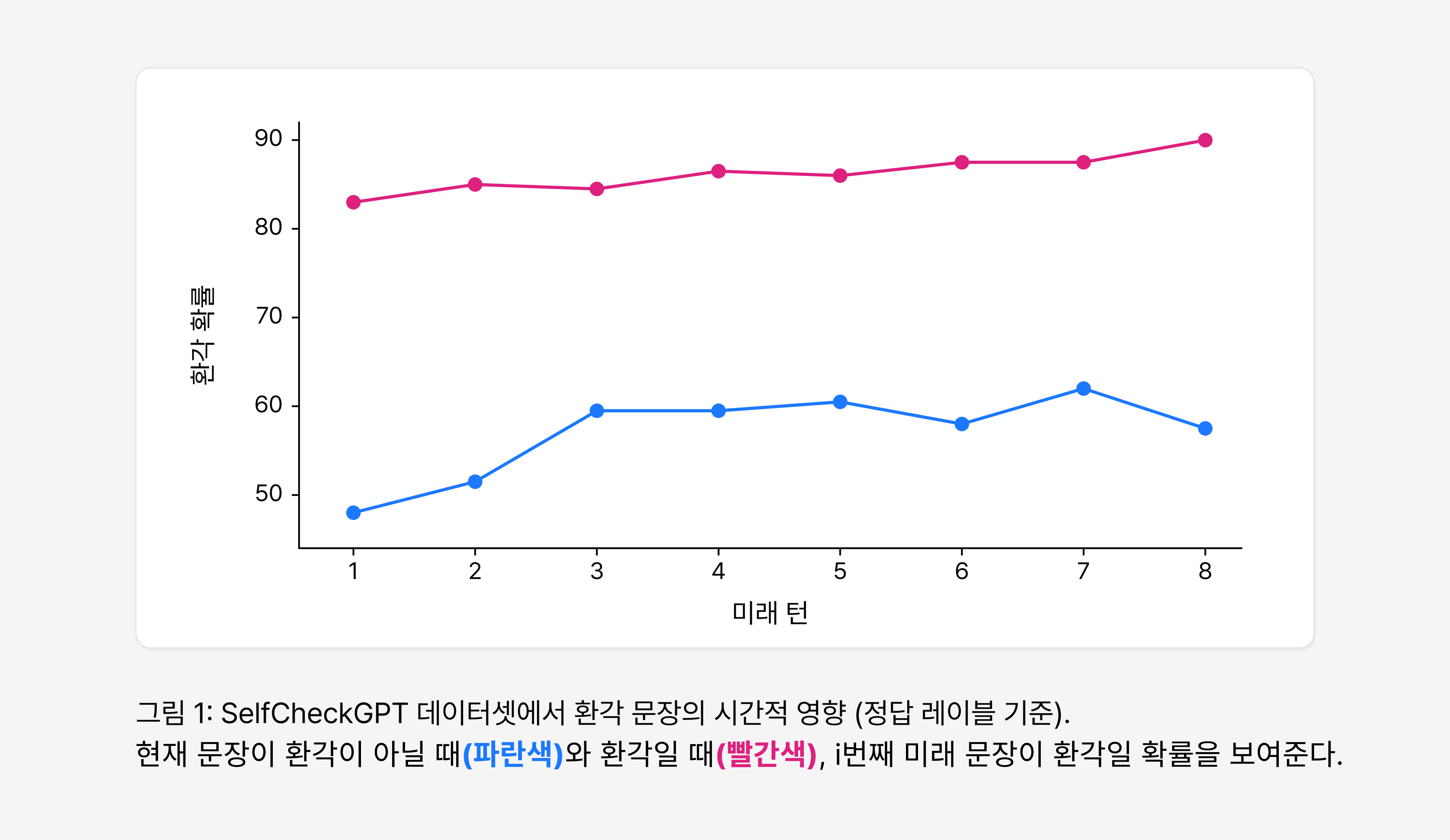
실제로 Figure 1에서도 이러한 경향이 확인됩니다. 현재 문장이 환각 상태(Hallucinated)일 때, 이후 문장들 역시 환각일 확률이 더 높게 나타났습니다. 특히 이후 문맥이 길어질수록 그 영향이 유지되거나 오히려 강화되는 패턴도 관찰되었습니다.
즉 환각은 하나의 문장에 고립되어 존재하는 것이 아니라, 이후 문맥 전체에 흔적을 남기며 전파될 수 있습니다.
미래 문맥 샘플링: 다음 문장을 먼저 생성해 보기
우리가 제안하는 방법의 핵심 아이디어는 비교적 단순합니다. 현재 문장이 환각인지 판단하기 어렵다면, 그 문장 이후에 이어질 미래 문맥(Future Context)을 먼저 생성해 보고 이를 추가 단서로 활용하는 것입니다. 이를 위해 논문에서는 환각 검출용으로 사용하는 별도의 LLM(Detector LLM)을 활용합니다. Detector LLM은 현재 문장 뒤에 이어질 가능성이 있는 미래 문장들을 샘플링하고, 이렇게 만들어진 미래 문맥을 현재 문장의 환각 여부를 판단하기 위한 추가 단서로 사용합니다.
전체 파이프라인은 다음과 같습니다.
- 이미 생성된 응답에서 검증 대상 문장을 선택합니다.
- 해당 문장 뒤에 이어질 미래 문장을 Detector LLM으로 샘플링합니다.
- 생성된 미래 문맥을 기존 환각 검출 방식의 입력에 함께 추가합니다.
- 이를 기반으로 현재 문장이 사실인지, 혹은 환각인지 판단합니다.
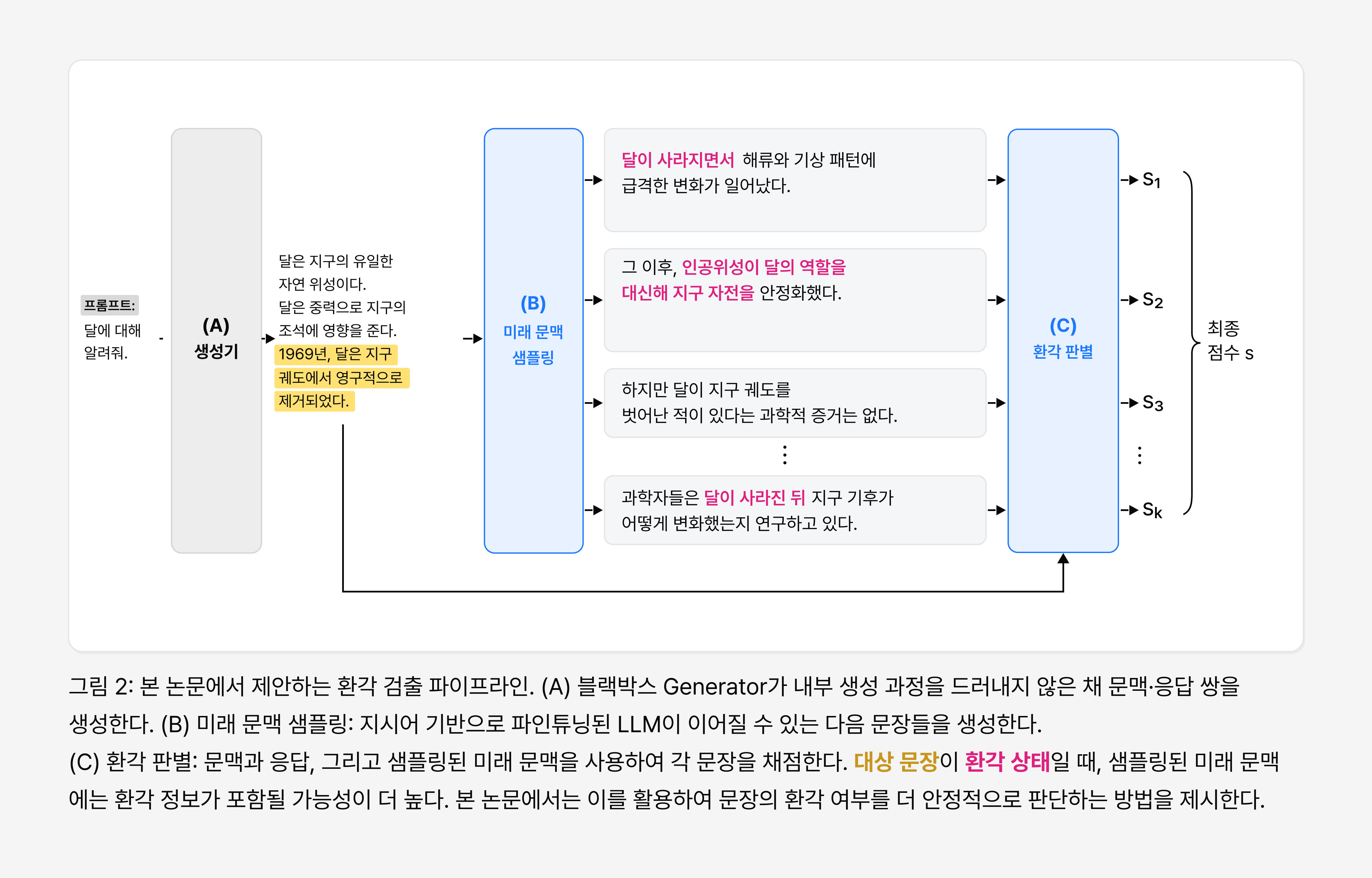
논문의 그림 2는 이러한 과정을 잘 보여줍니다. 먼저 내부 정보에 접근할 수 없는 생성 모델인 블랙박스 Generator가 응답을 생성하면, 별도의 Detector LLM이 ‘특정 문장’ 이후에 등장할 수 있는 미래 문맥을 샘플링합니다. 이후 이 미래 문맥을 환각 판별(Hallucination Detection) 과정에 활용하여 현재 문장의 환각 여부를 판단합니다.
미래 문맥은 기존 방식과 어떻게 결합될까?
논문에서는 미래 문맥(Future Context)을 기존 환각 검출 방식에 결합하는 세 가지 방법을 제안합니다.
1) Direct + Future Context
Direct는 Detector LLM에 현재 문장이 사실인지 직접 판단하도록 요청하는 가장 단순한 방식입니다.
기존에는 현재 문장과 이전 문맥만 활용했다면, 본 논문에서는 여기에 미래 문맥까지 함께 제공합니다. 이를 통해 모델은 ‘해당 문장이 이후 문맥에서 얼마나 자연스럽고 일관되게 이어지는지’까지 함께 고려할 수 있습니다.
2) SelfCheckGPT + Future Context
SelfCheckGPT는 동일한 질문에 대해 여러 개의 대체 응답을 생성한 뒤, 검증 대상 문장이 여러 응답에서 얼마나 일관되게 등장하는지를 확인하는 방식입니다.
여기에도 미래 문맥을 추가합니다. 즉, 단순히 여러 대체 응답만 비교하는 것이 아니라, 이후 문맥이 어떤 방향으로 이어지는지까지 함께 활용해 현재 문장의 사실성을 판단합니다. 이때 미래 문맥은 일관성을 판단하기 위한 추가 단서 역할을 수행하게 됩니다.
3) Self-contradiction + Future Context
Self-contradiction(SC)은 원래 문장과 새롭게 생성한 대체 문장 사이에 논리적 모순이 존재하는지를 분석하는 방식인데요.
모순 여부를 판단하는 과정에도 미래 문맥을 함께 제공합니다. 현재 시점에서는 잘 드러나지 않던 불일치가 이후 문맥에서 더 뚜렷하게 나타날 수 있으며, 환각 여부 역시 더 쉽게 식별할 수 있습니다.
즉 미래 문맥은 특정 환각 검출 방식 하나에만 적용되는 아이디어가 아니라, 기존의 다양한 블랙박스 기반 환각 검출 방법에 공통으로 결합할 수 있는 추가 단서로 활용될 수 있습니다.
실험 결과: 미래 문맥은 실제로 환각 검출에 도움이 될까
논문에서는 LLaMA 3.1, Gemma 3, Qwen 2.5를 Detector LLM으로 사용하였으며, 논리적 환각에 초점을 맞춘 SelfCheckGPT, SC-ChatGPT, SC-GPT4, SC-LLaMA, SC-Vicuna 데이터셋과 사실적 환각을 다루는 True-False 등 다양한 데이터셋에서 실험을 수행했습니다.
Table 1의 결과를 보면, 대부분의 설정에서 미래 문맥을 추가한 방식(+f)이 기존 환각 검출 방법보다 더 높은 AUROC 성능을 보였습니다. 예를 들어 LLaMA 3.1을 Detector로 사용한 경우, Direct 방식의 평균 AUROC는 68.9였지만 미래 문맥을 추가하면 71.1까지 상승했습니다. Self-contradiction(SC) 방식 역시 기존에는 65.7이었으나, 미래 문맥을 함께 사용했을 때는 70.8까지 개선되었습니다.
이는 미래 문맥이 현재 문장의 사실성을 판단하는 데 유의미한 추가 단서로 작용한다는 점을 보여줍니다. 특히 단순히 현재 문장만 분석하는 것보다, 해당 문장이 이후 문맥에서 어떤 방식으로 이어지는지까지 함께 고려할 때 환각 여부를 더 효과적으로 식별할 수 있음을 시사합니다.
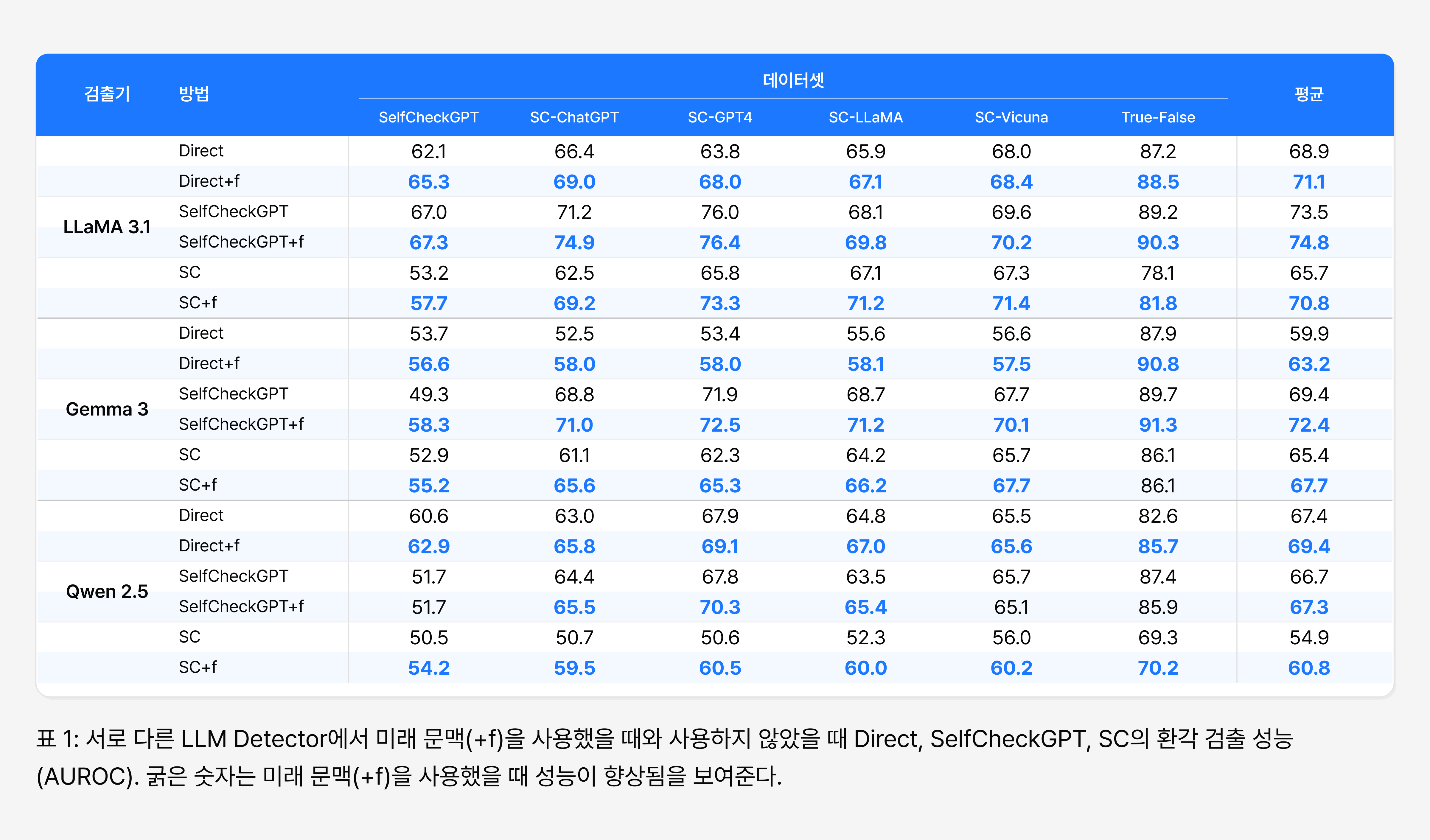
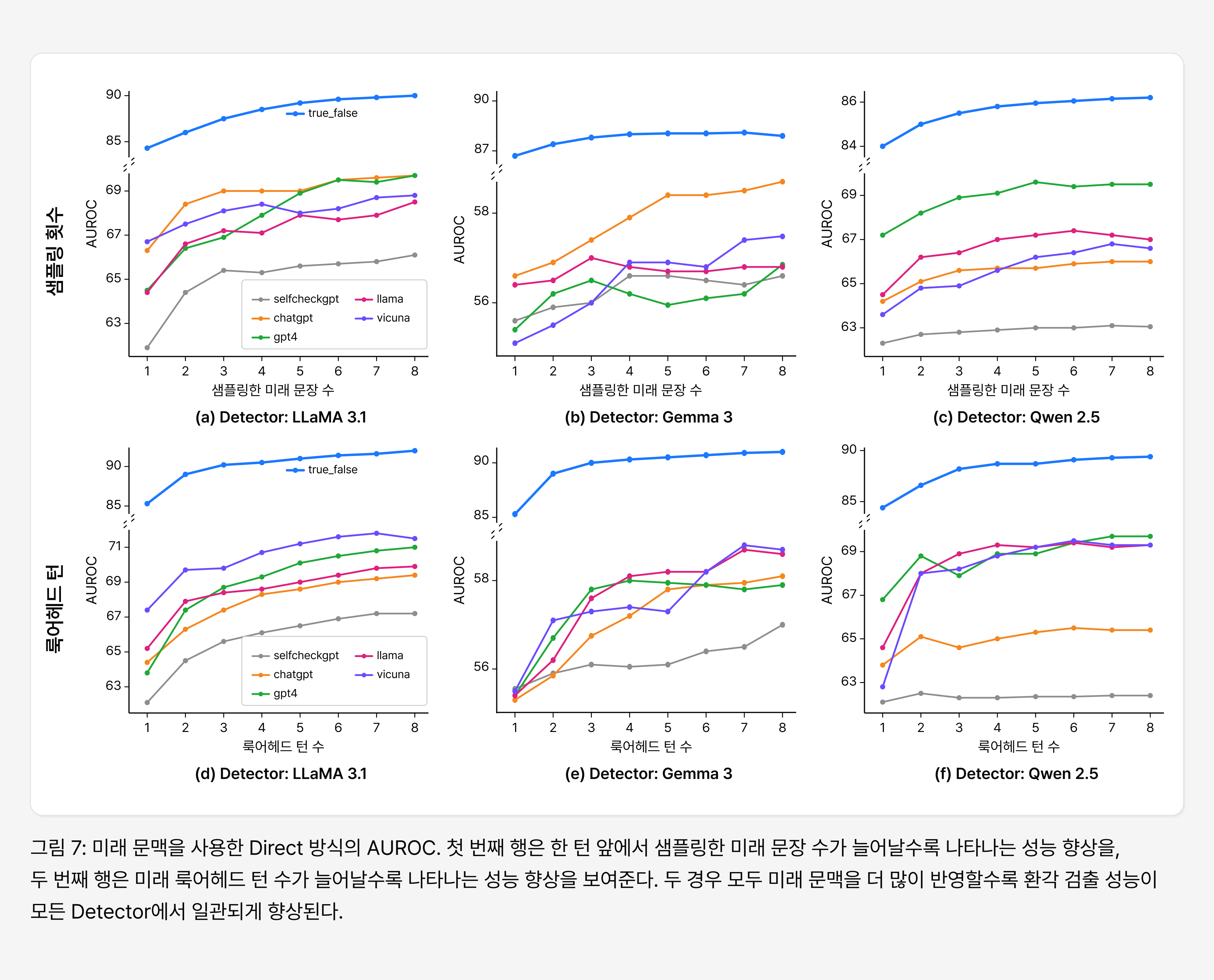
그림 3에서는 미래 문장을 더 많이 샘플링할수록 환각 검출 성능이 전반적으로 향상되는 경향이 나타났습니다. 이는 미래 문맥을 여러 방향으로 생성해 볼수록, 모델이 특정 오류를 이후 문맥에서 어떻게 이어가는지를 더 잘 관찰할 수 있기 때문입니다. 특히 환각 문장은 이후 문맥에서 불안정하게 확장되거나 서로 다른 방향으로 모순을 만들어낼 가능성이 높습니다. 즉 환각은 하나의 문장에 고립되어 존재하는 문제가 아니라, 이후 생성 과정 전체에 영향을 남기며 퍼져나갈 수 있습니다.
왜 미래 문맥이 환각의 단서가 될까
미래 문맥이 효과적인 이유는 단순히 정보를 더 많이 제공하기 때문만은 아닙니다.
핵심은 환각이 하나의 문장에만 고립되어 존재하지 않는다는 점입니다. 현재 문장이 환각이라면, 그 문장을 기반으로 이어서 생성된 이후 문맥 역시 환각일 가능성이 높습니다. 반대로 현재 문장이 사실에 기반한 내용이라면, 이후 문맥 또한 비교적 사실적인 방향으로 이어질 가능성이 높죠.
논문의 분석 결과 역시 이러한 경향을 보여줍니다. 현재 문장과 미래 문맥이 모두 환각이거나, 반대로 모두 사실에 기반한 내용일수록 미래 문맥이 환각 검출 성능 향상에 더 큰 도움을 주는 것으로 나타났습니다. 즉, 현재 문장의 특성이 이후 문맥에도 이어지는 경우가 많았고, 이러한 일관성이 환각 여부를 판단하는 중요한 단서로 활용될 수 있었습니다.
이는 미래 문맥이 단순한 부가 정보가 아니라, 현재 문장의 사실성을 추론하기 위한 일종의 간접 증거(Indirect Evidence)로 작동할 수 있음을 의미합니다. 다시 말해 현재 문장만 따로 떼어보는 것이 아니라, 그 문장이 이후 문맥을 어떤 방향으로 끌고 가는지까지 함께 살펴볼 때 환각을 더 효과적으로 식별할 수 있다는 것입니다.
환각 검출의 새로운 단서, 미래 문맥
기존의 환각 검출 방법들은 주로 현재 문장, 이전 문맥, 대체 응답, 혹은 외부 검색 결과를 활용해 환각 여부를 판단해 왔습니다. 반면 본 논문은 현재 문장이 이후에 만들어낼 미래 문맥(Future Context)을 새로운 환각 검출 단서로 활용합니다.
이 접근의 가장 큰 장점은 생성 모델의 내부 정보 없이도 동작할 수 있다는 점입니다. 또한 기존 샘플링 기반 환각 검출 방식들과 비교적 쉽게 결합할 수 있으며, 상대적으로 적은 비용만으로도 의미 있는 성능 향상을 얻을 수 있습니다.
무엇보다 이 논문은 LLM 환각을 바라보는 관점 자체를 조금 다르게 제안합니다. 단순히 ‘현재 문장이 사실인가?’만 판단하는 것이 아니라, ‘이 문장이 이후 문맥에 어떤 영향을 남기는가?’를 함께 살펴봅니다. 한 번 생성된 오류는 이후 문맥에도 영향을 남기며, 그 흔적은 다음 문장들 속에서 반복되거나 확장될 수 있기 때문입니다.
최근에는 AI가 생성한 블로그 글, 검색 응답, 요약 콘텐츠 등 다양한 형태의 AI 콘텐츠가 빠르게 증가하고 있는 만큼, 이를 신뢰할 수 있는 방법 역시 함께 발전해야 합니다. 미래 문맥 기반 접근은 환각 검출을 위한 새로운 가능성을 보여주는 동시에, 더 안전하고 신뢰할 수 있는 AI 활용 환경을 만드는 데 기여할 수 있을 것입니다.