
This post introduces a NAVER Cloud paper, Enhancing Hallucination Detection via Future Context, to be presented at ACL 2026—the top conference in natural language processing (NLP) and artificial intelligence (AI)—held this July in San Diego, California.
Lee Joosung (NAVER Cloud)
Park Cheonbok (NAVER Cloud, KAIST)
Jo Hwiyeol (NAVER Cloud)
Kim Jeonghoon (NAVER Cloud, KAIST)
Park Joonsuk (NAVER Cloud, NAVER AI Lab, University of Richmond)
Why does LLM hallucination detection matter?
LLMs are now woven into everything from question answering and document drafting to blog content and summarization. Their responses keep getting more fluent and persuasive—but sounding plausible isn’t the same as being accurate.
The text an LLM generates can contain events that never happened, false cause-and-effect, claims that contradict earlier context, or unverified information. This is commonly called hallucination.
The problem gets harder in settings where only the final output is published, like blog posts or online articles. We have no way of knowing which model produced the text, what prompt was used, or what probability distribution it drew on to build each sentence. We’re left having to judge whether content is a hallucination in a black-box setting, with no access to the generating model’s internals.
Say a user asks, “Can I claim both the monthly-rent tax credit and the credit-card deduction on my year-end tax settlement?” If the model gets the tax law wrong early on, the rest of its explanation will likely build on that faulty premise. In short, one small error ends up contaminating everything that follows.
Where existing hallucination detection falls short
Methods for detecting LLM hallucination fall into a few broad families.
The first is uncertainty-based methods. These look at how low a probability the model assigned when generating a particular token, or how low its internal confidence was—essentially, how sure the model was about what it was saying. But this requires access to the model’s internals, like its logits or token-level probabilities. For models served only through an API, or for external content that’s already been generated, that information is often out of reach.
The second is sampling-based methods. These regenerate several responses to the same question and check how consistent they stay with the original. SelfCheckGPT is the best-known example: it generates multiple alternative responses, then analyzes whether a given sentence shows up repeatedly across them. The assumption is that fact-based content tends to recur in similar form across samples, while a hallucination tends to waver in wording or contradict itself from one sample to the next.
A third approach judges hallucination using documents retrieved through search. But retrieval-based methods have their own limits. They add the cost of search, and the quality and reliability of the results aren’t guaranteed—retrieved documents may be outdated or inaccurate, and the information you need may not exist on the public web at all. When the relevant evidence lives in restricted places—internal company documents, private knowledge bases, in-house policies, or the inner workings of a particular service—search alone rarely turns up enough to go on.
With these constraints in mind, the paper proposes a black-box hallucination detection method that relies on neither search nor the generating model’s internals.
The core idea: Hallucinations propagate into future context
One of the paper’s most striking observations is that when the current sentence is a hallucination, the sentences that follow are more likely to be hallucinations too.
Suppose a model generates the following sentence.
“In 1969, the Moon was permanently removed from Earth’s orbit.”
This is plainly false. Yet an LLM tends to carry that faulty premise naturally into the sentences that follow.
“Since then, artificial satellites have taken over the Moon’s role in stabilizing Earth’s rotation.”
“Scientists are studying how Earth’s climate adapted after the Moon disappeared.”
Once a false statement appears, the text that follows builds on the error, generating more false content on top of it. The paper calls this the snowball effect: small errors accumulate as generation continues, expanding into larger hallucinations downstream.
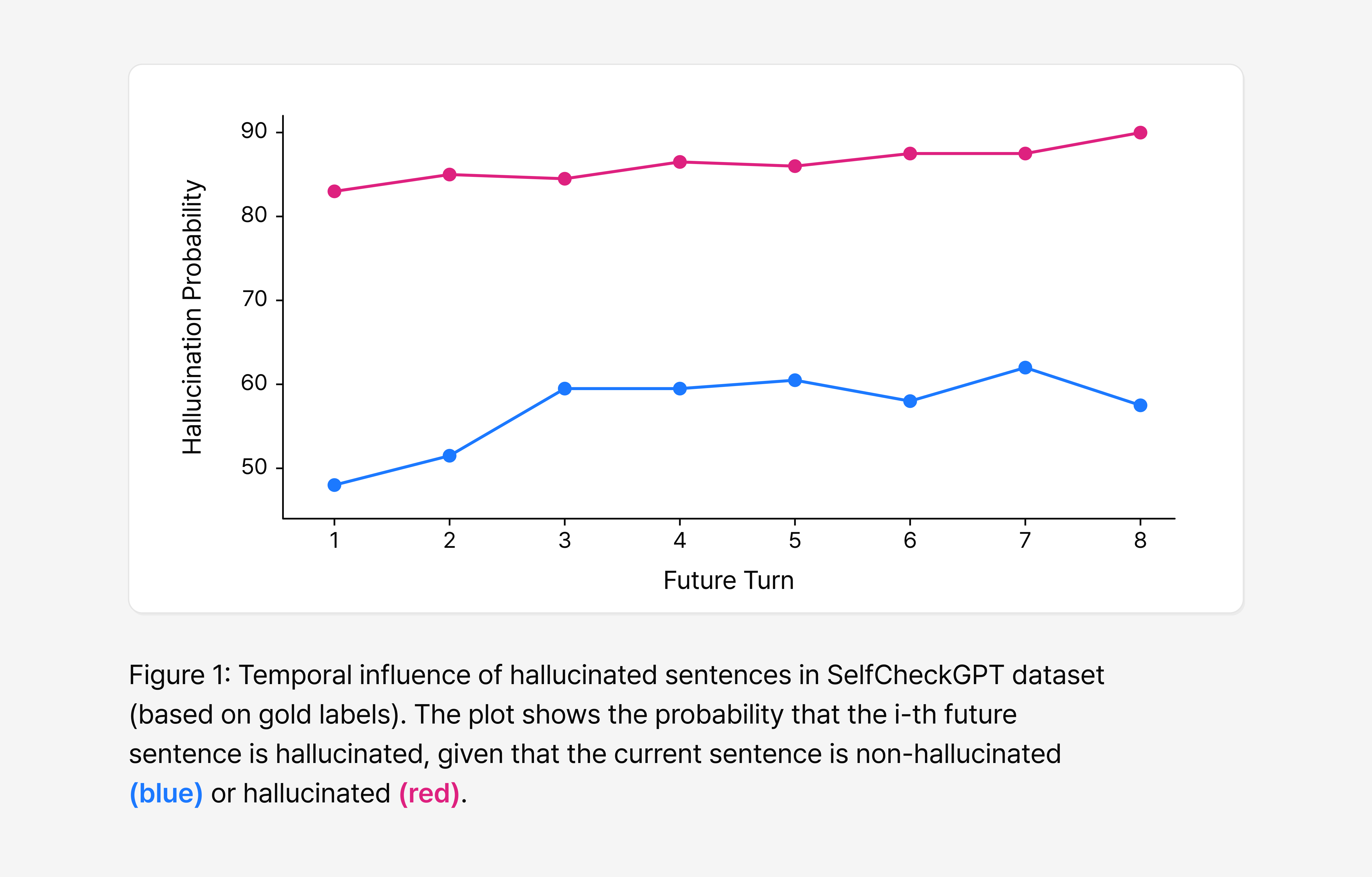
Figure 1 bears this out. When the current sentence is hallucinated, later sentences show a higher probability of being hallucinated as well—and as the following context grows longer, that effect tends to persist or even strengthen.
In other words, a hallucination doesn’t stay isolated in a single sentence—it leaves a trace across the context that follows and propagates from there.
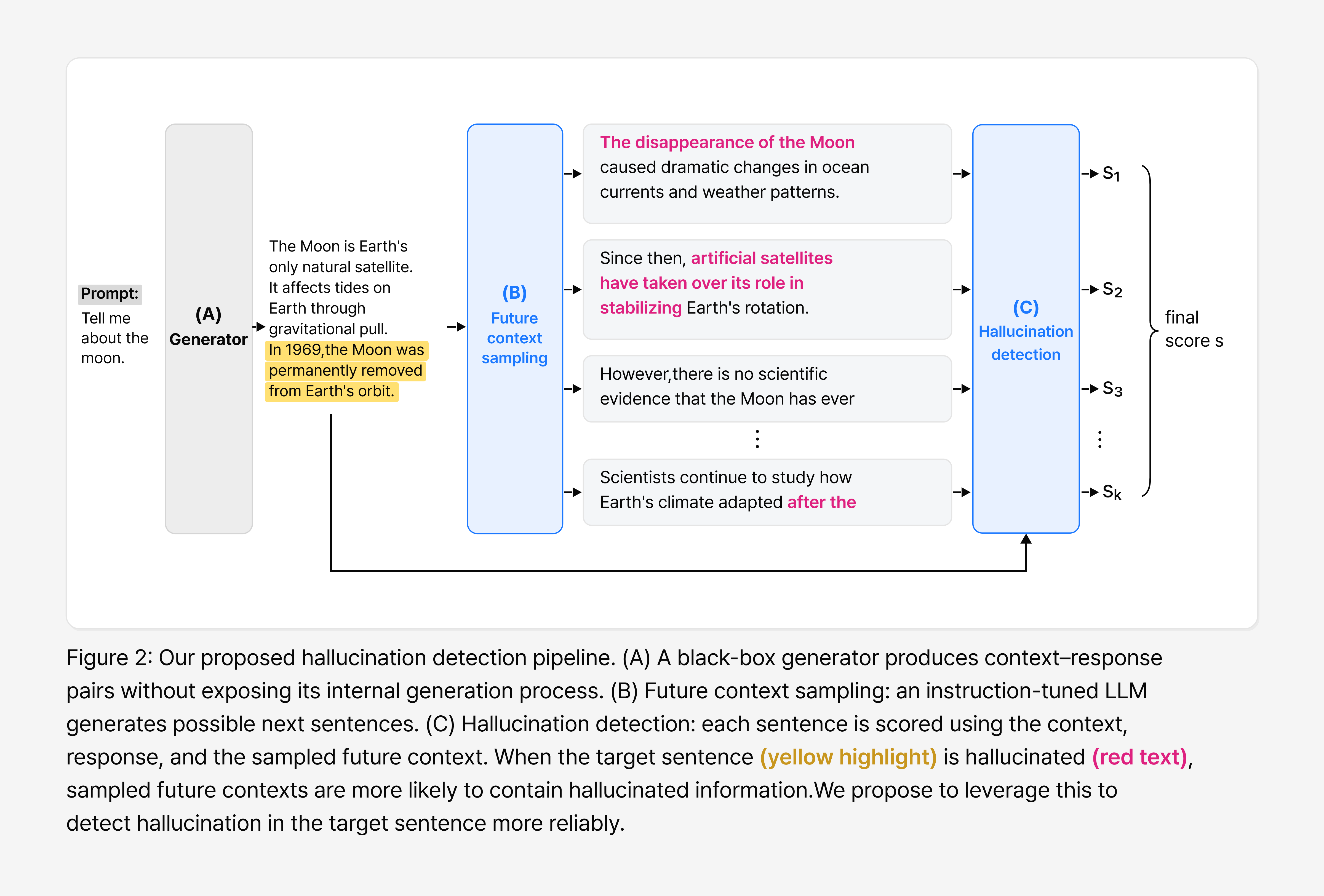
Future context sampling: Generating the next sentence first
The idea behind our method is fairly simple. When it’s hard to tell whether the current sentence is a hallucination, we first generate the future context that would follow it and use that as an extra clue. To do this, we use a separate LLM dedicated to detection (the detector LLM), which samples the sentences likely to come after the current one. That generated future context then becomes an added signal for judging whether the current sentence is a hallucination.
The full pipeline works like this:
- Select the target sentence to verify from an already-generated response.
- Sample the future sentences that would follow it, using the detector LLM.
- Add the generated future context to the input of an existing hallucination detection method.
- Use that combined input to judge whether the current sentence is factual or a hallucination.
Figure 2 illustrates this process. First, a black-box generator—a model whose internals we can’t see—produces a response. A separate detector LLM then samples the future context that might appear after a target sentence. That future context feeds into hallucination detection, which judges whether the current sentence is a hallucination.
How future context combines with existing methods
The paper proposes three ways to combine future context with existing hallucination detection methods.
1) Direct + future context
Direct is the simplest approach: it asks the detector LLM to judge directly whether the current sentence is true.
Where the original method used only the current sentence and the preceding context, we also supply the future context. That lets the model weigh how naturally and consistently the sentence carries into what comes next.
2) SelfCheckGPT + future context
SelfCheckGPT generates several alternative responses to the same question, then checks how consistently the target sentence appears across them.
We add future context here too. Rather than comparing alternative responses alone, we also use the direction the following context takes to judge the current sentence’s factuality—giving us one more angle on its consistency.
3) Self-contradiction + future context
Self-contradiction (SC) analyzes whether a logical contradiction exists between the original sentence and a newly generated alternative.
Here too, we provide future context while judging contradiction. Inconsistencies that aren’t obvious at the current point can surface more clearly in the following context, making hallucinations easier to spot.
Future context isn’t tied to any one detection method—it’s a supplementary signal that pairs with a range of existing black-box detection methods.
Results: Does future context actually help?
The paper uses LLaMA 3.1, Gemma 3, and Qwen 2.5 as detector LLMs, and runs experiments across a range of datasets—SelfCheckGPT, SC-ChatGPT, SC-GPT4, SC-LLaMA, and SC-Vicuna, which focus on logical hallucination, along with true-false and others that address factual hallucination.
In Table 1, adding future context (+f) yields a higher AUROC than the original detection methods in most settings. With LLaMA 3.1 as the detector, for instance, the direct method’s average AUROC rose from 68.9 to 71.1, and self-contradiction (SC) improved from 65.7 to 70.8.
This shows that future context is a meaningful aid in judging a sentence’s factuality. Weighing how a sentence carries into the following context—rather than analyzing it in isolation—makes hallucinations easier to identify.
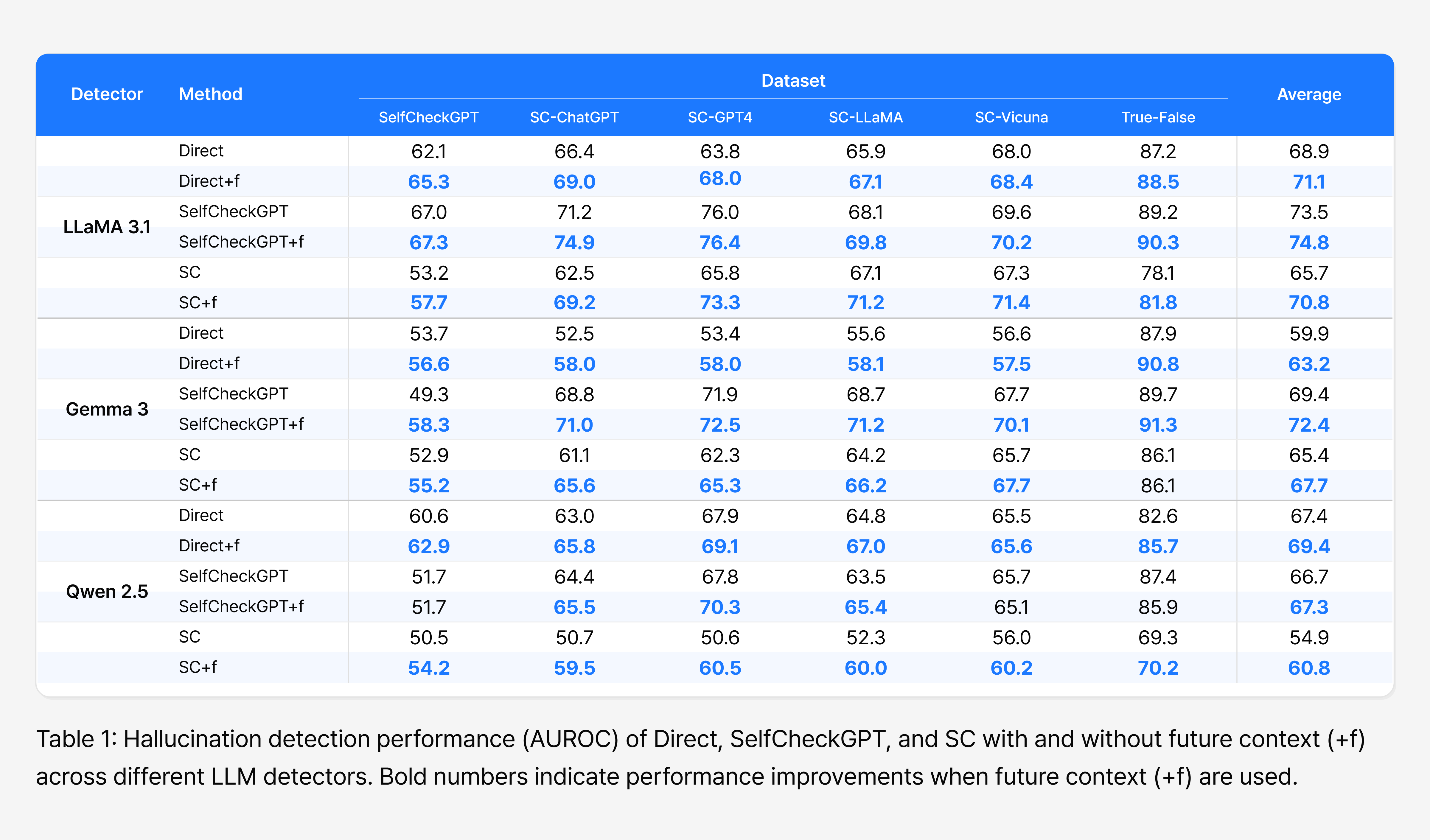
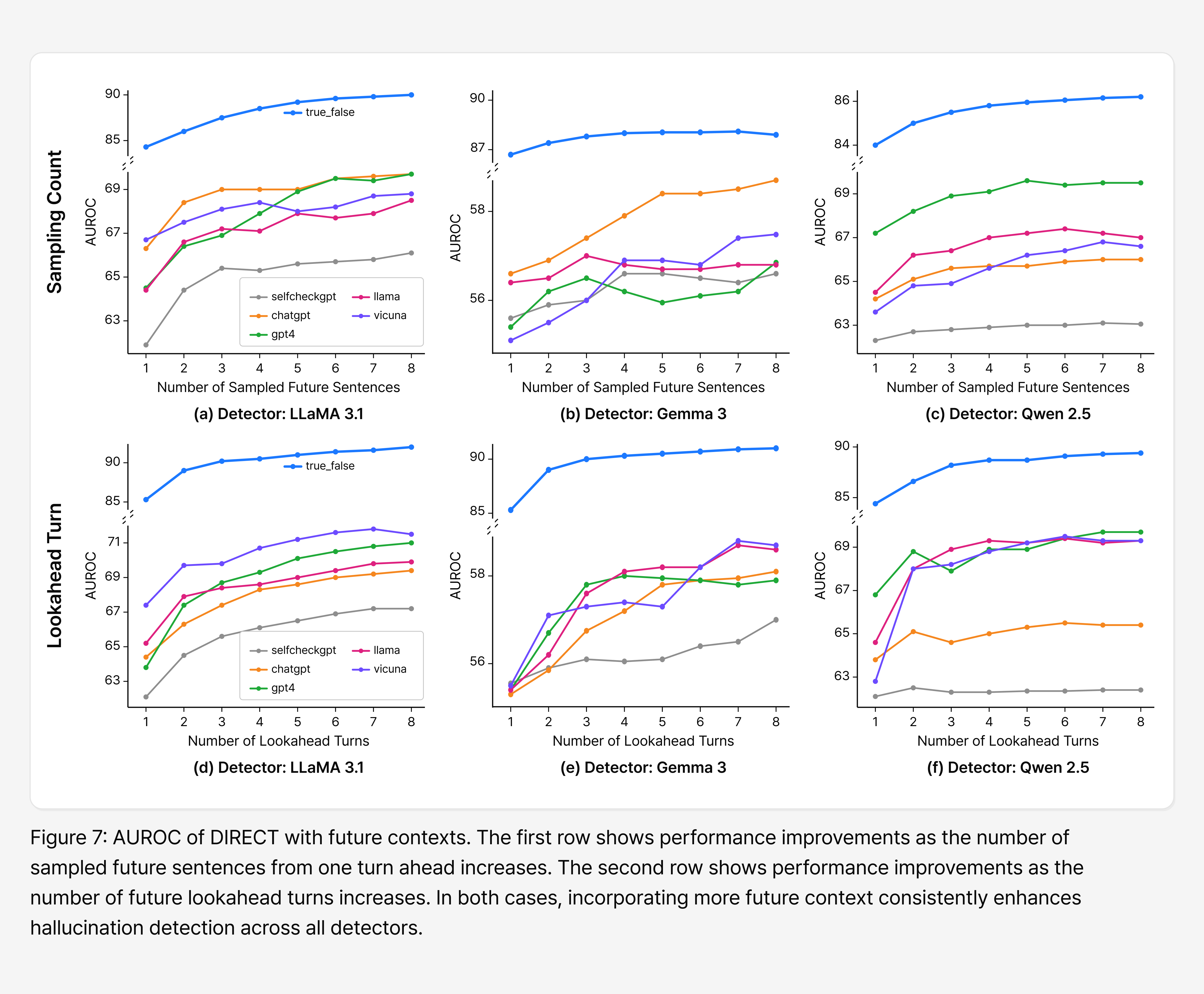
Figure 3 shows that sampling more future sentences generally improves detection. Generating future context in more directions lets the model observe how a given error plays out downstream—and hallucinated sentences are especially likely to expand unstably or contradict themselves as the text branches out.
Why future context works
Future context isn’t effective just because it supplies more information.
The key is that a hallucinated sentence rarely stands alone. If the current sentence is a hallucination, the context generated on top of it is likely to be hallucinated as well. Conversely, if the current sentence is grounded in fact, the following context tends to continue in a relatively factual direction.
Our analysis confirms it. Future context helped detection most when the current sentence and the future context were both hallucinated, or both grounded in fact. The character of the current sentence usually carried into the following context, and that consistency turned out to be a strong indicator for judging hallucination.
So future context isn’t just supplementary information—it can act as a kind of indirect evidence for inferring the current sentence’s factuality. Rather than examining the current sentence on its own, we can identify hallucinations more effectively by also watching the direction it pushes the following context.
Future context: A new clue for hallucination detection
Existing detection methods have mostly judged hallucination using the current sentence, the preceding context, alternative responses, or external search results. This paper instead uses the future context a sentence will go on to produce as a new clue for detecting hallucination.
The biggest advantage of this approach is that it works without any access to the generating model’s internals. It also combines fairly easily with existing sampling-based detection methods, delivering meaningful gains at relatively low cost.
More than anything, the paper proposes a slightly different way of looking at LLM hallucination. Instead of asking only “Is the current sentence true?”, it also asks “What effect does this sentence leave on the context that follows?” Once an error is generated, it leaves a mark on the later context, and that trace can repeat or expand across the sentences that come after.
As AI-generated content—blog posts, search answers, summaries—grows quickly, the ways we verify its trustworthiness need to keep pace. A future-context approach points to new possibilities for hallucination detection, and to a safer, more reliable environment for using AI.